

STING – Synthesis and analysis with Transducers and Invertible Neural Generators
Human communication is rich and varied, drawing on abstract concepts, grammatical rules, speech melody, facial expressions and body gestures to convey meaning. In this project we develop a unified machine-learning framework that accounts for the entire range of modalities, and that works equally well for analysing and generating human communication. This brings together theory and methods from here-to separate research fields, and creates new opportunities for detecting and managing bias.
Popular scientific summary
Novelty
State-of-the-art computer avatars and robots can be made to look and sound human, but interacting with them is not as easy and natural as it is to have a conversation with another human. Computers are frustratingly clueless about the meaning of the words we say to them, and act oblivious to our tone of voice. When avatars themselves speak, we can hear that they do not actually get the point of what they are saying. Sometimes they even make no sense at all. Scientists are working hard to improve the situation, but progress is difficult because no-one has the full picture.
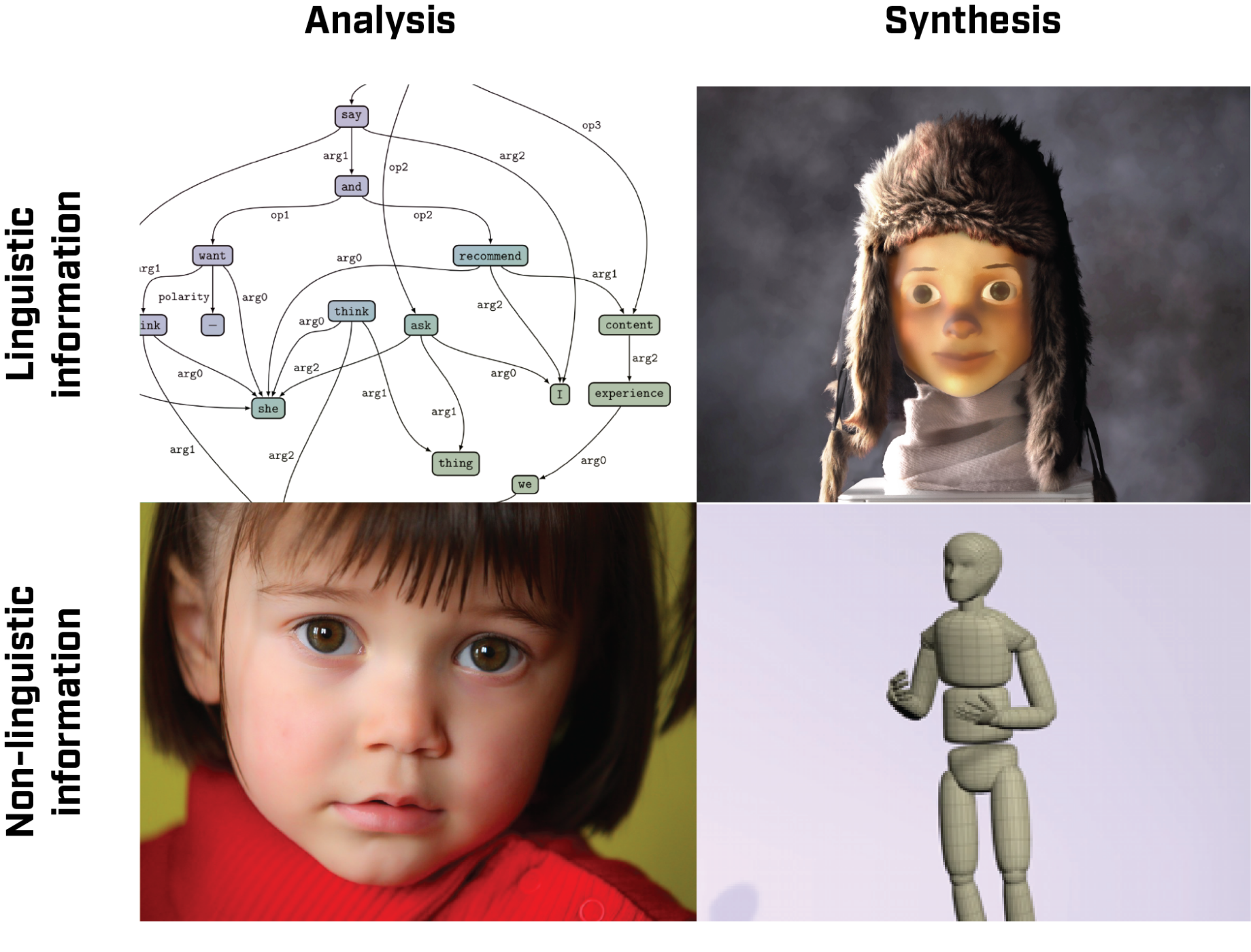
On the inside, artificial humans contain many different parts with different responsibilities – recognising words, understanding what they mean, formulating things to say, and actually speaking them are separate bits of the entire system, as are the bits that deal with body language, emotions, and facial expressions. Figure 1 shows four important types of problems that are typically solved by different parts of systems. The parts are only loosely connected, and are built separately, by different teams of scientists and engineers that do not talk much to each other. This is completely different from how humans function, and how our abilities to speak and listen, and to understand and use body language, all learn from each other as we grow.
Teams and synergy
We are a number of AI scientists doing research on different aspects of artificial humans, and we think it is a real problem that our fields are not working more closely together. We have formed a team, called STING, to change that. Together, we combine expertise from all four quadrants in Figure 1. The three nest nodes (KTH, Linköping, Umeå) contribute different aspects of the competences necessary for successfully pursuing the project goals. The KTH team has long experience with machine learning, simulation, and invertible models. Linköping contributes expertise in natural language processing, including both discrete and continuous models for analysing and producing language. The Umeå team are experts in grammatical frameworks, multi-modal data analysis, and discrete models, and also contributes experience with work on fairness and equality.
Our plan is to create methods for both recognising and generating human behaviour, together with the processes of extracting meaning and expressing meaning — the four problems in Figure 1 – all at the same time. Our vision is to unify everything artificial humans need to do into one integrated package, for machines to learn to see and listen better, and answer us with meaningful words and body language of their own.
Excellence
Since the unified system that we are aiming for will be bi-directional, it is easier to study. We can more easily detect why something went wrong, and we can ask the system to illustrate examples of different behaviours it has learned to recognise. This makes it much easier to fix problems, and we can get an explanation when something goes wrong. We can use this to ensure that they are free of prejudice and treat everyone fairly, instead of repeating biased behaviour they may learn from us. We will also show what these new ideas can do for you and for society introducing our research into computer games, to create characters that are more fun and engaging to interact with, and improve existing patient simulations in hospitals, to train doctors to give you better care.
Scientific presentation
Background
To efficiently collaborate with humans, artificial agents need to interpret multimodal signals and express themselves in a natural manner. This includes the analysis of speech and affect from non-verbal cues, as well as the synthesis of spoken utterances from an underlying communicative intent, and their pairing with human-like non-verbal behaviour consistent with attitude and intention.
All of these tasks have received substantial research focus, motivated by unmet needs for, e.g., collaborative manufacturing robots, immersive video game characters, and intelligent digital assistants.Advances in deep learning have enabled data-driven methods for modelling such highly complex signals, but these have not been integrated with semantic models able to capture meaning. Similarly, research on models for, e.g., voice synthesis is largely separate from research on models for affective computing, facial expression analysis, etc. Moreover, the leading models for many of the above problems are essentially black boxes. This is a pressing issue, since systems based on these models often lack robustness outside the laboratory, reaching biased decisions and exhibiting catastrophic failures that are showstoppers when deploying AI in the real world.
Our central thesis is the need for a framework that treats all aspects and tasks in human communication jointly, and lets all the modalities enrich each other. Such a framework should also by design provide affordances for addressing explainability and fairness concerns.
Purpose
The current state of multimodal analysis and synthesis of human communication is summarised by the four quadrants in Figure 1. To date, tasks with discrete outputs and tasks with continuous-valued outputs live in separate worlds. The former tend to use symbolic formalisms such as transducers, while deep learning is overwhelmingly favoured for the latter. Also, analysis and synthesis use separate methods and are usually trained on disjunct datasets. Very few approaches have tried to pursue analysis and synthesis, or discrete and continuous outputs, in a common framework.
In this project, we will develop a framework for invertible probabilistic models that unify both analysis and synthesis capabilities, on discrete as well as continuous modalities.This entails two interlocking technical challenges, namely (1) supporting invertibility while (2) integrating representations of discrete data into the continuous methods favoured in deep learning.
Methods/chosen approach
To address challenge (1), we use methods such as normalising flows, which employ invertible neural networks to learn mappings between observed signals and factorised latent representations. These methods have recently been extended to discrete-valued data, which makes it possible to address challenge (2). Through demonstrators of practical utility in industry and/or healthcare, we will demonstrate our advances and the benefits they bring both in terms of explainability and fairness. To pursue our multi-disciplinary research agenda, we bring together expertise from all four quadrants in Figure 1 – experts on continuous data at KTH and on discrete representations at LiU and UmU. We also draw on UmU’s experience with the analysis and mitigation of bias in learned models.
NEST environment description
The staff of the NEST consists of the six applicants: Gustav Henter and Hedvig Kjellström at KTH, Marco Kuhlmann at LiU, and Henrik Björklund, Johanna Björklund, and Frank Drewes at Umeå University. In addition to these, three postdocs are to be recruited. To transfer competence between the nodes, the postdoc researchers will rotate among the participating research groups. This serves to transfer competencies and inject new ones, and forms a backbone to weave additional collaboration activities around, e.g., joint workshops, seminar series, and PhD course development.
At KTH, we will create a hotspot focused on probabilistic methods for structured representation learning, which will leverage the world-leading research environments at TMH and RPL. For LiU, we plan to create a local WASP hotspot at the Department of Computer Science for research activities around the mathematical foundations of mixed continuous–discrete models of computation, as we will develop them for this NEST.
The UmU hotspot will be linked to the multidisciplinary Language Processing Center North, and to WARA Media and Language which is currently hosted at Umeå University. We further draw on our ongoing collaboration with the Umeå Center for Gender Studies. There are also collaboration opportunities with the Umeå Institute of Design which has repeatedly been ranked as one of the world’s top design institutes.
The project gains visibility by showcasing the resulting technology in some of the world’s best known video games: In preparation for this proposal, we discussed the project with the AI/ML teams at EA Games, King, and Coldwood. Since top-end games are often meant to be replayed and offer several routes through the story, it is desirable that the characters’ behaviour is stochastic and varies with each play-through. Our approach has the potential to deliver practical means of automatically generating such behaviour, and there is a general interest among the industry partners to engage with the project and try our solutions.
Contact
Gustav Eje Henter
Assistant Professor, Division of Speech, Music and Hearing, KTH Royal Institute of TechnologyPeople
PI and Coordinator: Gustav Henter is an Assistant Professor at the Division of Speech, Music and Hearing at KTH Royal Institute of Technology. He received a PhD from KTH in 2013 and moved on to a post-doc position at the Centre for Speech Technology Research (CSTR) at the University of Edinburgh, UK, followed by another post-doc in Prof. Junichi Yamagishi’s research group at the National Institute of Informatics in Tokyo, Japan. He returned to KTH in April 2018, first as a post-doc and then, from January 2020, as an assistant professor.
Henter’s primary research interests are probabilistic modelling for data generation, particularly 1) speech synthesis (text-to-speech) and 2) data-driven computer animation (body motion and co-speech gesticulation). Applications of the former include virtual assistants, prostethic voices, phonetics research, and assistive technologies for the visually impaired, and for the latter films, games, virtual avatars, social robots, and research on human-computer interaction.
Co-PI: Hedvig Kjellström is a Professor in the Division of Robotics, Perception and Learning at KTH Royal Institute of Technology. She is also a Principal AI Scientist at Silo AI, Sweden and an affiliated researcher in the Max Planck Institute for Intelligent Systems, Germany. She received an MSc in Engineering Physics and a PhD in Computer Science from KTH in 1997 and 2001, respectively, and thereafter worked at the Swedish Defence Research Agency, before returning to a faculty position at KTH.
Kjellström’s present research focuses on methods for enabling artificial agents to interpret human and animal behavior. These ideas are applied in the study of human aesthetic bodily expressions such as in music and dance, modeling and interpreting human communicative behavior, the understanding of animal behavior and cognition, and intelligence amplification – AI systems that collaborate with and help humans.
Co-PI: Marco Kuhlmann is a Professor at the Department of Computer and Information Science at Linköping University, where he leads the Natural Language Processing Group. His current research focuses on studying the computational properties and the information encoded in neural language models and developing techniques for grounding these models in non-textual sources such as images and knowledge graphs. Kuhlmann holds a PhD in Computer Science from Saarland University (2007) and an MSc in Cognitive Science and Natural Language from the University of Edinburgh (2002).
Before coming to Linköping, Kuhlmann worked as a postdoctoral research fellow at Uppsala University (2008–2013). His work has been recognized with the E. W. Beth Dissertation Prize of the Association for Logic, Language and Information (2008) and a Google Faculty Research Award (2016).
Co-PI: Henrik Björklund is an Associate Professor at the Department of Computing Science at Umeå University. He has a background in theoretical computer science and his current research mainly concerns various aspects of Natural Language Processing, such as theoretical work on the mechanisms underlying discrete language models. In collaboration with Gender Studies scholars, he is currently involved in investigating bias (gender bias, ethnicity bias, etc.) in language models and how it can be mitigated.
Björklund received his PhD in Computer Science from Uppsala University in 2005. After that, he worked as a postdoc for six months at the RWTH Aachen and then as a researcher and teacher for 3.5 years at the TU Dortmund, before coming to Umeå as an assistant professor in 2009, becoming a senior lecturer in 2013, and an associate professor (docent) in 2014.
Co-PI: Johanna Björklund is an Associate Professor at the Department of Computing Science at Umeå University. Her research is on semantic, or human-like, analysis of multimodal data, incorporating, e.g., images, audio, video, and text. She is also a co-founder of the media tech companies Codemill and Adlede which deliver products and services for the media supply chain and count ViacomCBS, BBC, and ProSieben among their customers. Björklund received her PhD in Computer Science at Umeå University in 2007.
After her dissertation, Björklund worked for a period of time at Dresden University as a research assistant at the chair of Prof. Vogler, before returning to Umeå and a position as first a junior and later a senior lecturer, becoming a Docent in 2016. Her work is supported by the Swedish Research Council, the Swedish Defence Research Institute, Vinnova, and various EC funding programs. She is managing the Wallenberg Research Arena for Media and Language, which is part of the research program Wallenberg AI, Autonomous Systems and Software Program (WASP).
Co-PI: Frank Drewes is a professor at the Department of Computing Science at Umeå University with a background in theoretical computer science, focusing on the study of advanced finite-state systems for the generation and transformation of trees, graphs, and pictures. About a decade ago, he embarked into the application of these methods – in particular the theory of graph transformation – to natural language semantics.
Drewes received his PhD from the University of Bremen in Germany in 1996 with the predicate summa cum laude. Four years later, he accepted an offer to move to Umeå University as a senior lecturer, where he became an associate professor (docent) in 2003 and a full professor in 2010.