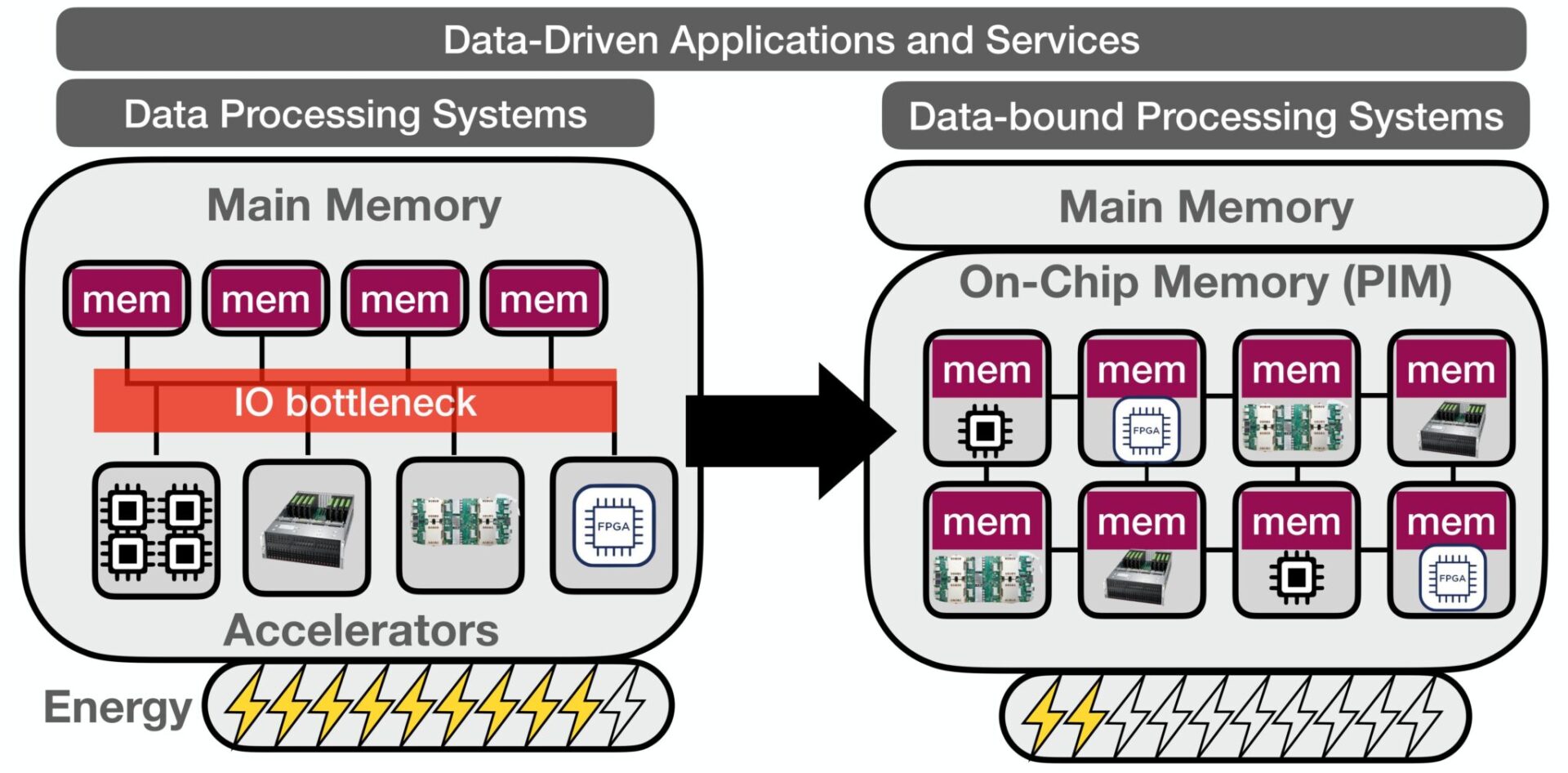
NEST-project Data-bound computing
The current AI revolution is driven by our ability to collect, store and process huge amounts of data. However, even the most recent generation of computing systems is struggling to keep up with the continuously increasing data volumes. Current hardware is optimized for computations rather than for data processing, and the resulting mismatch between computer architectures and the new data-driven software wastes significant resources. Today, the design and training of a single neural network may consume the same amount of energy as 4000 Toyota Camrys driving the 612 km between Stockholm and Malmö, and it is not uncommon that 80% of the training time for a deep neural network is devoted to data movement. Running modern data-driven workloads on compute optimized hardware is clearly not sustainable!
This project aims at developing the principles behind the next generation of computing systems, optimized for modern data-intensive workloads. Such systems require a comprehensive understanding of the full computing stack, from computer architectures, through distributed systems all the way to the applications running machine learning pipelines.
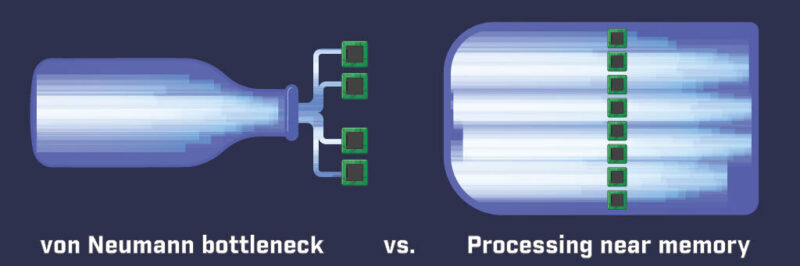
At the hardware level, the three principles that have powered the current generation of computers, Moore’s law (decreasing transistor sizes), Dennard scaling (increasing clock frequencies) and Amdahl’s law (parallelization speedups), have all run out of fuel. The most promising path to further improvements in performance, energy consumption and cost is to develop domain-specific processors. These processors do only a few tasks, but they do them extremely well. For data bound computing, we believe that these domain-specific processors will be built on the principle of processing-near-memory, rather than having computing and memory decoupled as in today’s standard processors.
The emergence of different accelerators will give rise to platforms that are much more heterogeneous than today’s standardized cloud services with their virtual CPUs and memory. This will be the pattern both at large scale and in the collections of tiny embedded processors that are gathering and processing data everywhere.
The significant changes in hardware required to sustain the growth in raw data processing performance cause a ripple of change to the software and algorithms that run on the top. Conversely, new algorithms and applications demand new developments in systems and architecture. The interplay between the different layers is complex, and building an efficient, well-functioning system demands a similar interplay between experts from the different layers.
Long-term Impact
Data bound computing is a quest for computer architectures and software systems that can support sustainable and scalable machine-learning for decades to come. At its core are four research groups with strong and complementary areas of expertise and a dedication to attack this challenge “full front”, from hardware to algorithms. With a strong track record in academic research, open-source software, innovation and industrial collaboration, we are uniquely positioned to put WASP and Sweden in the driving seat for the development of data-bound computing.
To maximize the scientific impact, we will publish at top-venues in computer architecture, programming languages, distributed systems and machine learning. We will educate our PhD students to have both deep domain knowledge and cross-cutting skills from collaborative demonstrator work. For broader impact, it is essential that non-researchers try out and adopt our ideas. We will therefore devote a significant effort to open-source software and demonstrator work. We will interact with industry and end-users to share project outcomes, learn from their feedback and elicit their ideas on how our research can make a difference for them.
Novelty
The Data-bound Computing project will take an interdisciplinary approach to build abstractions across the complete compute stack to manage parallelism and data locality in a novel way that is completely transparent to productivity programmers. In these systems, computations will be moved to where data resides, rather than the opposite approach adopted in current designs.
Excellence
The outcome of the project is a future-proof software/hardware stack for data-bound computing that will be competitive with the highest-performing computing systems at a significantly higher energy efficiency.
Synergy and team
At the core of this NEST are five principal investigators, with the joint expertise that is required to undertake this challenging project. Per Stenstrom, pioneer computer architect, will focus on the underlying PIM hardware architecture. In software, the proven expertise of Seif Haridi and Paris Carbone in distributed systems will attack the challenge of providing a reliable data-bound computing runtime. Mikael Johansson’s and Mary Sheeran’s respective competences in distributed optimisation algorithm design and declarative programming languages will contribute towards a complete system architecture with a powerful optimiser and a programming model that is declarative for diverse data analytics.
Scientific presentation
The shift from compute-centric to data-centric hardware has already begun. Accelerators such as GPUs and TPUs are commonplace, solid-state drives with enhanced on-board processing are beginning to appear, and soon it will be possible to create “chiplets” that integrate custom accelerators directly onto memory devices. We refer to this technology collectively as processing in memory (PIM). Our proposal is an interdisciplinary effort to accelerate the development of next-generation data-centric computing systems built on PIM. We will address challenges across the entire compute stack, from algorithms, via software frameworks and domain-specific programming languages, to computer architectures. More specifically, our efforts will revolve around the following scientific challenges:
1. Enabling massively-parallel data-centric chip architectures
The emergence of 3D-integrated memory devices with a logical layer enables the tight integration of accelerators (e.g. GPUs, TPUs) with memory devices into processing-in-memory (PIM) devices.
Today, it is possible to integrate on the order of ten such PIM devices on an interposer forming a chip delivering a performance of 1 TFLOPS and with 100-GB on-chip memory. With such powerful chips, one can scale-out to data-center size, approaching exascale performance with 250,000 nodes and 4 chips per node. However, the challenges in realizing such a chip architecture in a scalable manner involve strategies for maximizing data parallelism and data locality.
2. Scalable data-bound processing system software
In most modern scalable pipelines and services (software 2.0), application state is accessed in volatile memory or persistent storage while compute hardware is decoupled, including different accelerators suited for different tasks (e.g., multicore CPUs for business logic and transactions, and TPUs/GPUs for ML model training and serving). Computing accelerators communicate excessively through memory units, causing unnecessarily high IO and energy consumption. We believe that a careful integration of PIMs into existing adopted system technologies can offer an unprecedented boost in acceleration and energy-efficiency. To that end, we will investigate PIM-centric compilation strategies that can automate the generation of optimal execution plans while targeting support for diverse data-intensive workloads (e.g., stream, event-based, model-based). We further envision a redesign of execution schemes and algorithms (e.g., scheduling, relational/tensor operators, iterative optimisation, etc.) to fully exploit the potential of data-centric chip architectures.
3. End-to-end energy-efficient computing for data processing at scale
ML algorithms that are hard to tune and map onto current computer architectures result in an enormous waste of computational and engineering times. These effects are even more pronounced on distributed data sets and on energy-limited edge devices, where poor IO management congest shared communication resources and drain devices of energy. As a final cross-cutting challenge we aim maximize the energy-efficiency of the complete system from ML pipelines to chip-level code generation, accounting for energy cost for computing accelerators with direct on-chip memory access and the energy spent on IO between PIM units. We believe that a single carefully conceived architecture will be able to adapt to both edge and cloud computing scenarios.