

NEST-project: 3D Scene Perception, Embeddings and Neural Rendering
A longstanding goal of artificial intelligence is to recover a representation of the three-dimensional world which is semantically meaningful and geometrically faithful given sensory input data. Recent work has taken a big step towards this goal by showing that such representations can be learned, and it is now possible to automatically generate photorealistic imagery from an observed scene. This project will go further towards developing new theory and algorithms that would make it possible, not only to recognize and reconstruct a semantically and geometrically meaningful representation, but also to manipulate, modify and automatically complete a three-dimensional scene model of the visual world.
Long term impact
From the longterm perspective, the approach to modify, autocomplete and generate 3D scenes will be important for several Swedish companies, e.g., in the growing AR and VR sector. Volvo Cars and Zenseact are interested in efficiently generating realistic 3D training data to test systems for autonomous driving and driver assistance and H&M aims to create plausible compositions for deformable garments. The results will improve sustainable and environmentally friendly technological development. For instance, instead of overproducing products that might not be wanted by the customers, companies could generate realistic and dynamic 3D models to forecast demand.
Novelty
This project will develop new theory and algorithms for general-purpose neural network-based scene models, focusing on disentanglement, generalization and invariance which will enable 3D controllable models that incorporate dynamics and deformation. From a scientific viewpoint, this is an emerging field and so far, to a considerable extent an unexplored research area.
Excellence
The goal to modify, autocomplete and generate dynamic 3D scene models is an emerging field, and a better understanding and practical usage of disentangled representations are highly sought after, putting this WASP NEST at the international forefront. If the project will be successful, this would lead to a paradigm shift as 3D models will be more ubiquitous, flexible and can be used for extrapolation, and not just interpolation.
Synergy and team
The team of PIs consists of four renowned researchers with complementary skills:
Fredrik Kahl is a professor in computer vision and image analysis and one of the pioneers in developing modern optimization techniques for applications in computer vision.
Cristian Sminchisescu is a professor of applied mathematics at Lund University, with specialization in computer vision (semantic segmentation, human sensing) and machine learning (structured prediction).
Kathlén Kohn is a WASPAI/Math assistant professor with main research expertise in algebraic geometry, working on the mathematical foundations in computer vision, machine learning, optimization, and statistical inference.
Mårten Björkman is an associate professor at the division of Robotics, Perception and Learning at KTH with a long experience in selflearning robotic systems using latent embeddings for both sensor and action spaces.
Scientific presentation
Background
In recent years, generative neural network models for creation of photorealistic images have become increasingly popular, as a result of its many practical applications. It is now possible to automatically generate photorealistic imagery from an observed scene using an encoder-decoder model. Generative models are trained using large sets of examples from which the commonalities and variation between examples are learned. The results is a low dimensional latent space representation of a distribution from which new examples can be drawn and images be generated. However, for these generative models to be of practical use, they need to provide some degree of controllability. One way of doing this is to ensure that the latent representation is disentangled, so that different qualities of the resulting images are kept separate. For example, the shape of an object can be separated from its material properties, the viewing direction and the overall illumination. With such a representation, new images can be created by either directly controlling the qualities or by mixing qualities from different sources, such as taking the material of a tablecloth and replacing that of a dress.
Purpose
This project aims to develop new theory and algorithms that would make it possible, not only to recognize and reconstruct a semantically and geometrically meaningful representation, but also to manipulate, modify and automatically complete a three-dimensional scene model of the visual world.
Methods
This project will exploit recent research on so called neural radiance fields to produce implicit three-dimensional representations of objects and scenes, representations from which images can easily be rendered from arbitrary viewpoints. Such representations will simplify manipulation and make it more intuitive, while improving the robustness, interpretability, and generalization of models.
At the core of the project is the encoder-decoder model (Figure 1). The underlying research challenge addressed is to improve the robustness, interpretability, controllability, and generalization performance for models of this type.
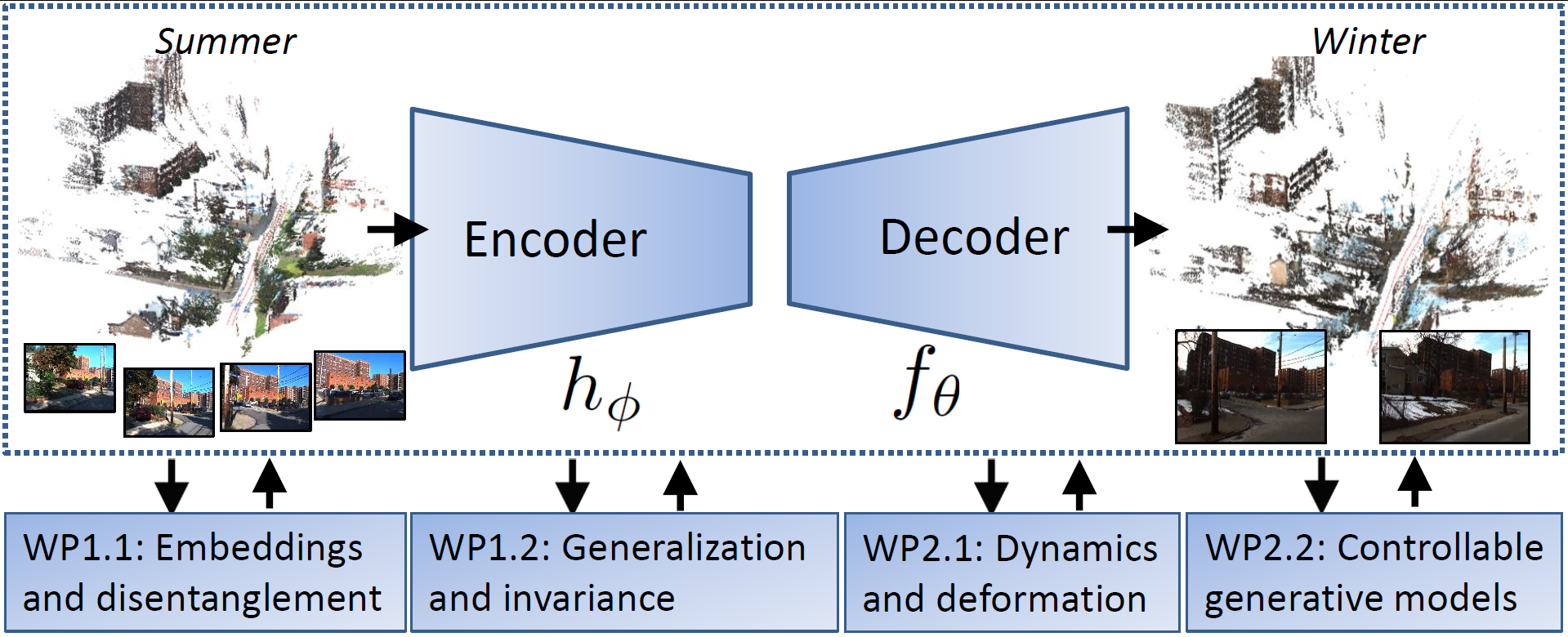
Work packages
The research is structured into two parts and each part has two work packages (WPs, Figure 1).
- 3D perception and scene understanding.
- WP1.1: Embeddings and disentanglement.
- WP1.2: Generalization and invariance.
- Manipulation and rendering based on flexible and controllable generative models.
- WP2.1: Dynamics and deformation.
- WP2.2: Controllable generative models.
The first part, 3D perception and scene understanding, is devoted to an area which has seen important advances in recent years and where the PIs have made significant contributions. Still, there is new methodology which is required to make the second part realizable. The second part, Manipulation and rendering based on flexible and controllable generative models focuses on a new emerging area which is largely unexplored. A more in-depth description of the methodology can be found at the project website below.
NEST environment
The project will be performed in close collaboration between academy and industry, to take the developed research and integrate it into industrially relevant prototypes. Focus will be on two scenarios:
Outdoor environments:
- Industrial collaborators: Volvo Cars and Zenseact.
- Hotspot: Chalmers, Göteborg.
- Demonstrator: System for efficient generation of varied validation data for improved testing methodology of sensors and training data for deep learning algorithms used in autonomous driving.
Indoor environments:
- Industrial collaborators: Wallvision and H&M.
- Hotspot: KTH, Stockholm.
- Demonstrator: 3D indoor mostly still life scene reconstruction and navigation for environments where some deformation is present in the form of oscillating flowers, curtains blown by the wind, etc. There will also be a collaboration with Wallvision, for improved AR technology targeting automatic replacement of wallpaper in indoor scenes.